- 객체와 테이블 매핑 : @Entity, @Table
- 필드와 컬럼 매핑 : @Column
- 기본키 매핑 : @Id, @GeneratedValue
객체와 테이블 매핑, 필드와 컬럼 매핑, 기본키 매핑의 방법을 간단하게 알아보고 각 애노테이션의 중요한 옵션들과 기능들에 대해서 알아보자.
객체와 테이블 매핑
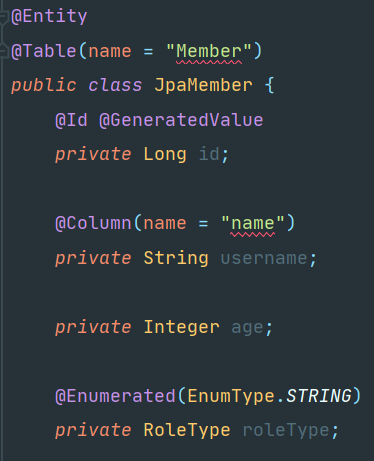
- @Entity가 붙은 클래스는 JPA가 관리하는 엔티티라고 한다.
- 기본 생성자가 필수이다.(파라메터가 없은 public또는 protected생성자) JPA기본 스펙이 이렇게 되어 있다.
- final 클래스, enum, interface, inner 클래스에 사용할수 없다.
- 저장할 필드에 final을 사용할 수 없다.
- name 속성 : 같은 클래스 이름이 없으면 가급적이면 기본값을 사용하자.
- @Table : 아래와 같은 기능이 있는 속성들을 가진다.

데이터베이스 스키마 자동 생성
spring.jpa.hibernate.ddl-auto=create- properties나 yml은 위과 같은 형식으로 옵션을 설정할 수 있다.
<property name="hibernate.hbm2ddl.auto" value="create" />- xml은 위와 같은 형식으로 옵션을 설정할 수 있다.
- DDL을 애플리케이션 실행 시점에 자동 생성해줄 수 있다.
- 테이블 중심의 개발에서 객체 중심의 개발을 할 수 있다.
- 데이터베이스 방언을 활용해서 데이터베이스에 맞는 적절한 DDL을 생성할 수 있다.
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>- 데이터베이스 방언? : dialect를 사용하여 value에 원하는 데이터베이스를 설정하면 그에 맞게 하이버네이트에서 자동으로 쿼리를 변경해준다. 예를들어 MySQL에서 VARCHAR인 타입은 Oracle에서는 VARCHAR2인데, 이러한 차이를 자동으로 변경해준다.
- 실무에서는 사용하지 말고 개발단계에서만 사용하자. (테이블의 변경에서 문제가 생기면 큰 장애가 발생...)

필드와 컬럼 매핑

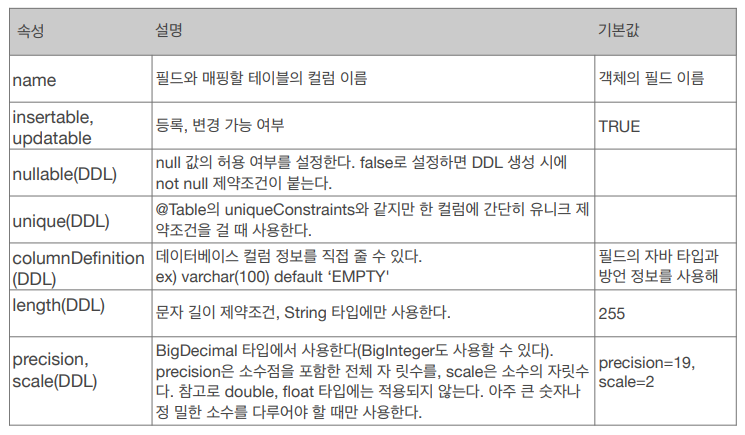

- @Temporal(TemperalType.DATE) 애노테이션은 Java8 이상부터 적용되는 LocalDate, LocalDateTime을 사용하게 되면, LocalDate는 Date타입으로(년,월,일) , LocalDateTime은 Timestamp타입으로 (년,월,일,시간) 인식된다.
- @Enumerated(EnumType.STRING) 애노테이션을 사용할 때, 옵션을 주의해야 한다. 디폴트옵션은 @Enumerated(EnumType.ORDINAL) 이다. 이는 Enum타입의 순서(index)를 사용한다. 이 방식에서의 문제점은 중간에 Enum타입에 값이 추가,변경 되었을 때 index값이 바뀐다는 것이다. 그러면 모든 데이터가 틀어지는 상황이 발생할 수도 있다. Enum타입을 사용할 때는 그냥 @Enumerated(EnumType.STRING)을 사용하자.
기본키 매핑
- @Id는 직접할당 방식으로 이 애노테이션을 사용하면 직접 PK값으로 등록한 것이다.
- @GeneratedValue는 자동할당 방식으로 전략에 따라 데이터베이스에 기본키 매핑방식을 위임한다.
- @Id나 @GeneratedValue로 등록하면 데이터베이스에 위임한 것이기 때문에 값을 등록하면 안된다. (코드에서 set하여 넣으면 안된다는 뜻)
@GeneratedValue의 전략
1. @GeneratedValue(strategy = GenerationType.IDENTITY)
- 기본 키 생성을 데이터베이스에 위임한다.
- Mysql을 사용하면 Auto Increase를 사용하여 만든다.
- 특징 : 이 전략을 사용하면 데이터베이스에 기본키 생성을 위임하기 때문에 영속성 컨텍스트에 영속(em.persist();)할 때, 기본키 값을 모른다! 1차 캐시에 담을 때 기본키를 key값으로 영속성 컨텍스트에 등록하기 때문에 발생하는 문제이다. 그래서 이 전략을 사용할 때에만 예외적으로 em.persist(); 하는 시점에 DB에 insert 쿼리가 날아가버린다.
2. @GeneratedValue(strategy = GenerationType.SEQUENCE)

- 시퀀스 오브젝트를 만들어 낸다.
- @SequenceGenerator(name = "MEMBER_SEQ_GENERATOR", sequenceName = "MEMBER_SEQ")
- 이와 같이 시퀀스 이름을 설정할 수도 있다.
- 특징 : 이 전략을 사용하면 영속성 컨텍스트에 영속(em.persist();)할 때, 매핑된 데이터베이스 시퀀스에서 시퀀스 값을 알아야 영속성 컨텍스트에 등록할 수 있다. (시퀀스 오브젝트는 DB가 관리하는 것이기 때문에 DB에 가봐야 알 수 있는 것이다.)
그래서 em.persist(); 할 때 DB에서 매핑된 데이터베이스 시퀀스에서 다음 시퀀스값을 먼저 얻어오고(call next value for SEQUENCE 하여 다음 시퀀스를 얻는 로그를 볼 수 있다.) 그 다음에 영속성 컨텍스트에 등록한다.
영속성 컨텍스트에 등록만을 한 것이기 때문에 트랜젝션을 커밋하기 전까지는 실제 쿼리가 날아가지 않는다.
* 의문점 : 그러면 영속성 컨텍스트에 영속을 할때마다 DB에 들러야하면 네트웤을 계속 타서 성능이 저하되는 것이 아닐까?
-> allocationSize 옵션을 이용한다.
allocationSize = 50 으로 지정해놓으면 call next value을 한번 하면 미리 50개의 사이즈를 디비에 올려놓고(DB는 시퀀스가 51번 부터 된다.) 메모리에서 1씩 사용하는 것이다. 50개 다쓰면 다시 50개 가져와서 사용한다. (DB는 시퀀스가 101번 부터 된다.)
이 때, 로그를 보면 call next value가 2번 호출된 것을 볼 수 있다. 이유는 첫 번째 call은 처음 DB에 들렀을 때 DB내부적으로 시퀀스 값을 1증가시켜서 가져온 값이고, 두 번째 call은 allocationSize가 50이기 때문에 DB시퀀스를 50까지 증가시켜 놓는 작업 위한 call이라고 이해하면 된다.
3. @GeneratedValue(strategy = GenerationType.TABLE)

- 키 생성 전용 테이블을 하나 만들어서 데이터베이스 시퀀스를 흉내내는 전략이다.
- 장점 : 모든 데이터베이스에 적용 가능하다.
- 단점 : 성능이 떨어진다.
- 특징 : SEQUENCE전략과 비슷하게 allocationSize옵션을 동일한 방식으로 사용할 수 있다.
4. 권장하는 식별자 전략
- 기본키 제약 조건 : null 아니고 유일, 변하면 안된다. 미래까지 이 조건을 만족하는 자연키는 찾기 어렵다. 대리키(대체키)를 사용하자.
- 권장 : Long형 + 대체키 + 키 생성전략 사용
'JAVA > Spring JPA' 카테고리의 다른 글
| JPA의 프록시와 연관관계 관리 (0) | 2022.01.03 |
|---|---|
| 상속관계 매핑과 매핑 정보 상속(@MappedSuperclass) (0) | 2021.12.30 |
| 다양한 연관관계 매핑 (0) | 2021.12.29 |
| 단방향 연관관계와 양방향 연관관계 (0) | 2021.12.28 |
| 영속성 컨텍스트 (0) | 2021.12.24 |